Table des matières
Introduction
Dans cette partie, nous allons montrer comment créer des programmes de tri sur des tableaux. Ces programmes sont basés sur des algorithmes de tri classiques enseignés dans toutes les filières de formation à la programmation.
Tri par sélection
Le tri par sélection consiste à parcourir un tableau de valeurs pour sélectionner la plus grande valeur et la placer en première position. Ensuite, il suffit de parcourir à nouveau le tableau pour placer la deuxième plus grande valeur et ainsi de suite.
Construction du tri par sélection
Programme AlgoTouch de tri par sélection
Voici un programme similaire réalisé avec la version web d’AlgoTouch. Dans ce programme les données sont triées par ordre croissant. Pour commencer, la plus petite valeur est placée en première position, puis la plus petite valeur suivante est placée en seconde position, etc. Contrairement à l’algorithme précédent, à une étape donnée i, l’algorithme utilisé cherche la position de la plus petite valeur (son indice) avant de la mettre à sa place par échange avec la position i. Dans la version précédente, à chaque fois qu’une valeur était plus petite que la valeur courante, on l’échangeait avec la valeur courante.
- triSelection effectue le tri complet;
- positionMin détermine la position de la plus petite valeur à partir de l'indice i;
- swap échange la valeur à l'indice i avec celle à la position min.
On peut lancer le programme triSelection soit en mode pas à pas, soit en mode automatique, soit en mode sans interruption. On peut aussi voir comment fonctionne le programme positionMin en le lançant après plusieurs étapes de triSelection. La encore, les modes pas à pas et automatique sont à privilégier.
Tri par insertion
Construction du tri par insertion
Programme AlgoTouch de tri par insertion
Voici une version du tri par insertion en AlgoTouch. Le principe général de l’algorithme reste le même: à l’étape k, la valeur a[k] est placée correctement dans le tableau. Les éléments d’indice inférieur à k sont décalés à droite par échange avec la valeur de a[k] tant qu’ils sont supérieurs.
- TriInsertion effectue le tri complet;
- InsereSuivant insère l'élément d'indice k;
- Echange échange les valeurs du tableau d'indices i et j.
On peut lancer le programme TriInsertion soit en mode pas à pas, soit en mode automatique, soit en mode sans interruption. On peut aussi voir comment fonctionne le programme InsereSuivant en le lançant après plusieurs étapes de TriInsertion. La encore, les modes pas à pas et automatique sont à privilégier.
Programme AlgoTouch de tri par insertion amélioré
- TriInsertion effectue le tri complet;
- InsererEltOrdreK insère l'élément d'indice k.
Tri à bulles
Le principe du tri à bulles est très simple. Parcourir un tableau, tant que deux éléments consécutifs sont non ordonnés, les échanger. Parcourir le tableau de données à nouveau et s’arrêter lorsqu’aucun échange n’a été effectué. Cela signifie que les éléments sont dans l’ordre.
Programme de tri à bulles
- TriBulles qui effectue le tri complet;
- Parcours qui effectue un passage sur le tableau pour effectuer des échanges si nécessaires.
Tri par séparation
Le principe du tri par séparation consiste d’abord à séparer le tableau de valeurs en deux parties puis à trier chacune des parties indépendamment. Un algorithme de séparation consiste d’abord à choisir une valeur, appelée pivot. Puis à placer toutes les valeurs inférieures ou égales à gauche du pivot et les valeurs supérieures à droite du pivot. Il suffit alors de trier la partie gauche puis la partie droite du pivot sur le même principe. Pour réaliser ce tri, on fait appel à une technique particulière appelée la “récursivité”.
Pour illustrer le principe de séparation, considérons le tableau d’entiers ci-contre. On choisit la première valeur (50) comme pivot.
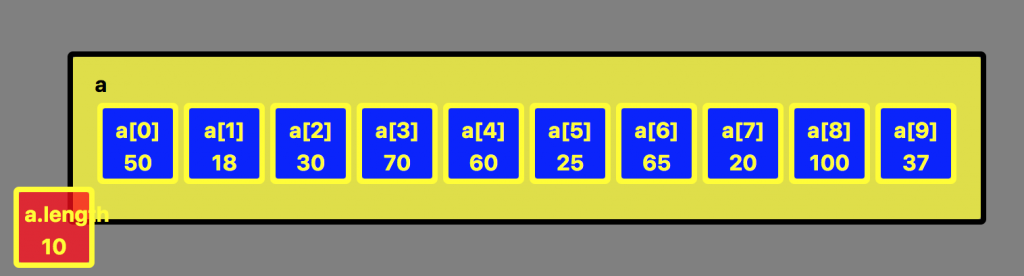
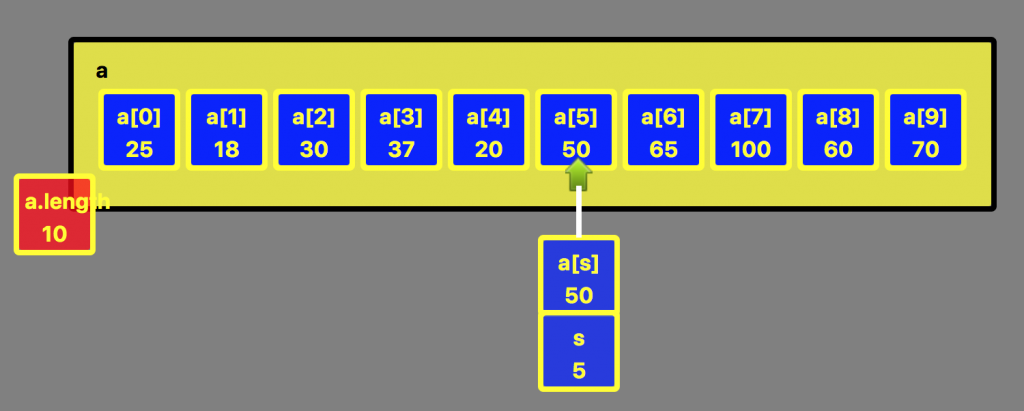
Après séparation, le pivot a été déplacé à l’indice 5. Toutes les valeurs d’indice inférieur sont inférieures au pivot et toutes les valeurs d’indice supérieur sont supérieures au pivot.
Le tri par séparation est le tri le plus rapide, on l’appelle communément QuickSort. Ce tri ne peut être réalisé directement avec AlgoTouch puisqu’il nécessite la prise en charge de la récursivité. C’est une notion extrêmement puissante mais non abordée dans le cadre que nous avons choisi : l’apprentissage de la programmation à des débutants. Cependant, nous pouvons programmer un algorithme de séparation des valeurs d’un tableau.
Un exemple de programme de séparation
Il existe de multiples façons de séparer un tableau. Voici par exemple un programme qui sépare un tableau a entre l’indice g et l’indice d.
Le principe est le suivant :
- on définit la valeur de a[g] comme pivot;
- on parcourt le tableau d’entiers de gauche à droite;
- tant que les valeurs sont inférieures ou égales au pivot, on avance;
- lorsqu’on trouve une valeur plus grande, on la place vers la fin de tableau. Pour cela, on l’échange avec t[d], et on décrémente d. Ainsi les valeurs supérieures au pivot seront placées à la suite depuis la fin du tableau jusqu’à d (exclu);
- le processus s’arrête lorsque la dernière valeur a été traitée.
Le résultat est un tableau dont toutes les valeurs “à gauche” sont inférieures ou égales au pivot et toutes les valeurs “à droite” sont supérieures au pivot. La variable s contient l’indice où a été déplacé le pivot. C’est donc l’indice qui désigne où s’est effectuée la séparation.
- Partition qui réalise la séparation du tableau entre les indices g (gauche) et d (droit). Le pivot est défini en g. En résultat, s est le nouvel indice du pivot, les valeurs d'indice inférieur à s sont inférieures ou égales au pivot et les valeurs d'indice supérieur à s sont supérieures au pivot;
- Adroite qui envoie "à droite" une valeur supérieure au pivot. Plus précisément, en fin de tableau à partir de l'indice d.
Avant de lancer le programme Partition, il faut vérifier que les indices g et d définissent bien les bornes du tableau de données à séparer.